Accessing SQL and NoSQL Databases with a GraphQL API

 Anant Jhingran
Anant JhingranAs some of you know, I have been working around databases for about four decades (that dates me!). From the early days of System R and Ingres, through the commercial engines of DB2 and Oracle, the open source MySQL and Postgres to the current generations of NoSQLs like MongoDB and Cassandra and scalable SQL like CockroachDB and Yugabyte — through all of this, anyone who ever predicted the demise of databases has been proven wrong.
SQL as the query language has persisted, evolved and improved, but the basic select * from foo where x = 1 group by y is the language known to hundreds of thousands of developers. Why is that? Because databases just work, and can we say that about many other things? The data in these databases power the digital products and experiences that you and I touch every day.
Accessing SQL, NoSQL Databases with a GraphQL API
Frontend developers put these digital experiences together, and they need the data in shapes that reflect business terms and concepts like Customer, Orders, Delivery Status. They need the data in the databases, but it is not necessarily intuitive, accessible or easily programmable. A real-world database schema might have hundreds of tables, normalized for update efficiencies and named for some fidelity to applications (I once saw a table named cust_01_x_t!).
As a query language, SQL binds tightly to expressing the user’s desire and is written with direct fidelity to the way databases are structured. Or take the NoSQL databases — Cassandra, MongoDB, Firestore, among others. Each has its own query language, and these query languages have bindings to the way data is stored and efficiently fetched. While many have languages similar to SQL, it is not SQL because SQL is simply not powerful enough to express the richness of the data stored in these systems. So while all databases are popular and work, they come with query languages that bind to the implementations. A wide variety of databases in an enterprise means a wide variety of languages and a cognitive overload of understanding the syntax and the optimization associated with each.
The View vs. the Implementation
Let’s take an example of something a developer building a digital experience might want to do: fetch customer information. So given their business needs, that frontend developer might fetch data from databases by writing something like this:
select concat (c.cust_first, ' ', c.cust_last) as name, c.contact_mail as email, a.street from cust_x_01 c, cust_x_01_addr a
where a.cust_id = c.base_num
…or something like this:
{
"customer": {
"name": "John Doe",
"email": "john.doe@example.com",
"addresses": [
{
"street": ...
}
]
}
}
Developers are voting with their feet, as they say. They are taking the latter approach, the GraphQL approach. It’s not difficult to see that the “shape” of the data is more aligned with what the developer needs for their application or experience.
But just because these developers are using GraphQL, it does not mean that the problem of converting the views they have to the implementations that the databases have goes away. So there are two ways to bridge the gap.
Databases Providing a GraphQL View
Consider Stargate, a GraphQL view on top of DataStax, the NoSQL database built on Apache Cassandra. It is a remarkable piece of technology that completely hides the data’s implementation in Cassandra with its view. The default sample that gets set up in DataStax is a list of Chipotle stores and their location. The query looks something like this:
type Query {
"""
Query for the table 'chipotle_stores'.
Note that 'state', 'latitude' and 'longitude' are the fields that correspond to the table primary key.
"""
chipotle_stores(
value: chipotle_storesInput
filter: chipotle_storesFilterInput
orderBy: [chipotle_storesOrder]
options: QueryOptions
): chipotle_storesResult
}
All the appropriate mappings to CQL are hidden from us, and we assume that because this is built by the Cassandra folks, they have done the proper optimization. So when a database provides a GraphQL interface, it is quite likely a good idea to use it.
Middle Tier Providing a GraphQL View
The database-only approach fails in a few cases:
- Some databases do not provide such a view. For example, while Cloud Firestore comes with a good REST interface, there is no GraphQL view.
- If you need to mix and match data from two different systems, then GraphQL from one database is good to have, but not sufficient. What you need is something like this:
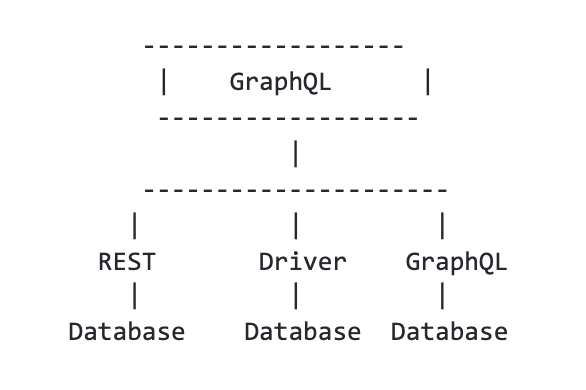
In other words, where the database provides a GraphQL interface, great; where it doesn’t, use its driver or other interfaces, like REST, to connect. Then mix and match when needed.
The layer that GraphQL-enables all the data must include important functional and non-functional characteristics. These include the ability to do translations between protocols, introspection, lightweight transformation and so on. On the non-functional side of the equation, there are performance optimizations. Many software systems, including the one from StepZen, are beginning to address these issues.
Summary: Add a GraphQL API Layer to Any Database
Databases store the world’s data and provide interfaces like SQL and its variants that let users access and manipulate the data. However, developers building digital experiences cannot, and should not, build out of these interfaces. Furthermore, GraphQL is turning out to be a natural language for accessing and manipulating the data. We thus have a divide between an implementation and a view that needs to be bridged.
The divide between the frontend and the backend can and must be bridged. We believe that databases providing GraphQL interfaces will bridge a part of the divide. But a middleware that speaks GraphQL on the top and native languages on the bottom will round out the solution. We will undoubtedly see tremendous innovation in this space in the next few years.
Originally published in The New Stack under the title: GraphQL: Bridging the Gap Between Databases and Your Apps 


