Bridging the Gap Between GraphQL and Databases

 Anant Jhingran
Anant JhingranDatabases have changed a lot over the years.
- Ingres, System R in the 70s
- Oracle, Sybase, DB2 in the 80s
- Postgres, MySQL in the 90s
- Cassandra, MongoDB in the 2000s
- Cockroach, Yugabytes in the 2010s
Over the course of that time, we've heard a lot of predictions of the end of the database. The truth is that databases are fundamentally important and the predictions of the death of databases have been greatly exaggerated. Today databases still store Exabytes of Data – 1,000,000 Terabytes!
But modern application development has actually presented new problems for our database systems. The core challenge today is: how do you make this data accessible to frontend applications that consume it in a way that the frontend developers require? For example, how do you translate data, which may come from multiple sources beyond just a database, into the objects that the frontend developers need to consume. In other words, how do you bridge the gap between the backend data and the frontend requirements?
GraphQL can be that bridge.
Balancing the Needs of the Frontend and the Backend
With REST you get what the API team wants you to get. By this, I mean that you get as little or as much data as the API chooses to expose, with no control over whether it includes a field you really need or excludes a field you don't. Whereas, with SQL, you can ask for anything but it requires that you write everything yourself, including often complex query logic to get what you need.
GraphQL in the middle has the perfect balance of light constraints but with great expressive power. Let's look at an example to illustrate this concept. The following GraphQL query could get a customers orders and the delivery status of each via a single query.
customer (email: “john.doe@example.com”) {
orders (status: “undelivered”) {
deliveryStatus {
expectedDate
signatureRequired
}
}
}
Compare that to REST where this might consist of multiple endpoint calls and subsequent code to stitch that data together. In SQL, you'd have to understand a complex table structure in order to construct the complicated join logic that would be required. Or imagine a scenario where the orders are in a database and the delivery status was from a third-party API like FedEx or UPS – now you've got a really complex problem to solve! GraphQL as a middle layer can solve all of these problems by abstracting away this complexity.
Impedance Mismatch - aka The Chunnel problem
The Chunnel, as you may know, has one end is in the UK and the other in France. The problem is that in the UK you drive on the left hand side and in France on the right. Somewhere in the middle you seamlessly transition from one side to the other. A similar problem happens between the how the data is presented in the backend of your application versus how the data needs to be consumed by the frontend application. It's what I call the "Chunnel problem" or the "impedance mismatch problem."
For instance, the following database diagram represents what is likely a common structure for storing customers and their orders in a relational database.
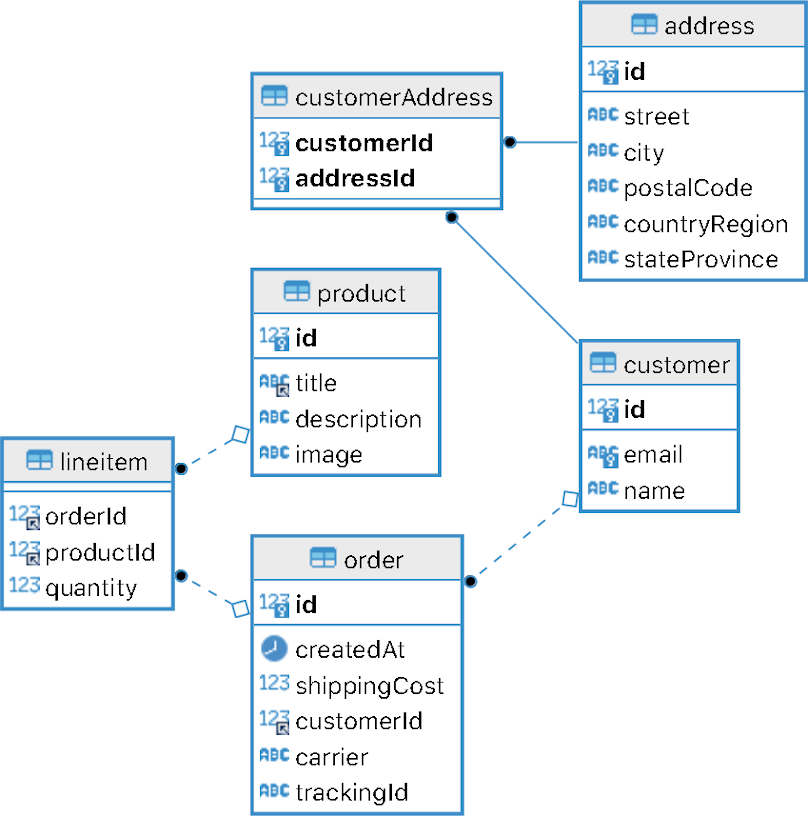
Notice that the data is scattered across multiple database tables. While this is done to meet the needs of performance, normalization, updates and more that the database requires, it makes no sense for a frontend developer who just wants to consume a Customer and Order object to display it to the end user. This problem is only exacerbated when data comes from multiple sources, like APIs, a CMS or a NoSQL data store, and not just from a database.
What you need is some middleware that can combine and mix and match data from your database with data from your other data sources into a single GraphQL endpoint that is easy for your frontend developer to consume.
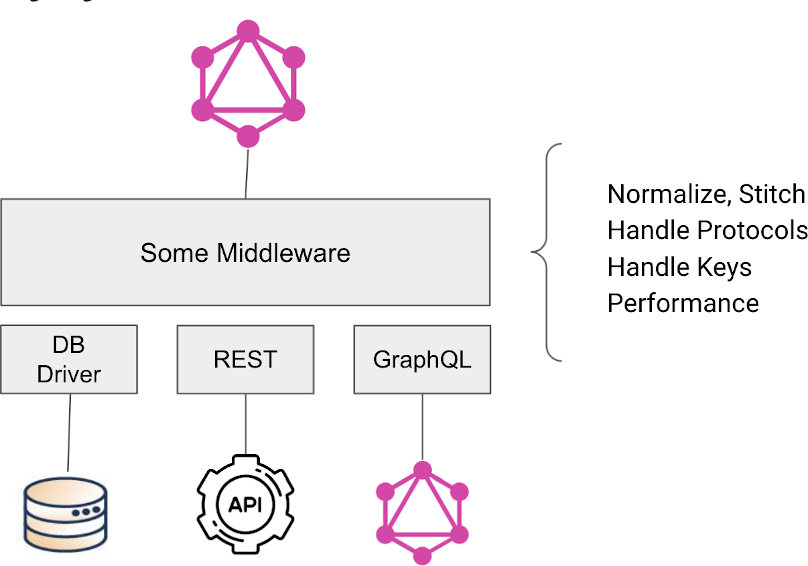
This middleware needs to be able to speak to the three different backends that are common – databases (of course!), REST APIs and other GraphQL APIs. But this middleware can't just connect to these backends, it needs to be able to translate between them to normalize data, stitch data together, handle different protocols, understand and manage the different keys and do all of this while optimizing for performance.
StepZen's Approach
StepZen has taken a unique approach to solving this problem. We provide a declarative approach for you to define the data you need from the different backends, while StepZen handles all the concerns around stitching, normalization, keys, caching and so on. This is done using three different connectors that are implemented and configured as GraphQL directives:
@dbqueryconnects a database backend to a StepZen schema. We have support for Postgres and MySQL at the moment, but more databases are coming soon.@restconnects any REST API to a StepZen schema. This can also connect to tings like Cassandra, MongoDB and Firebase, which all have REST-based APIs as well.@graphqlconnects another GraphQL API to a StepZen schema
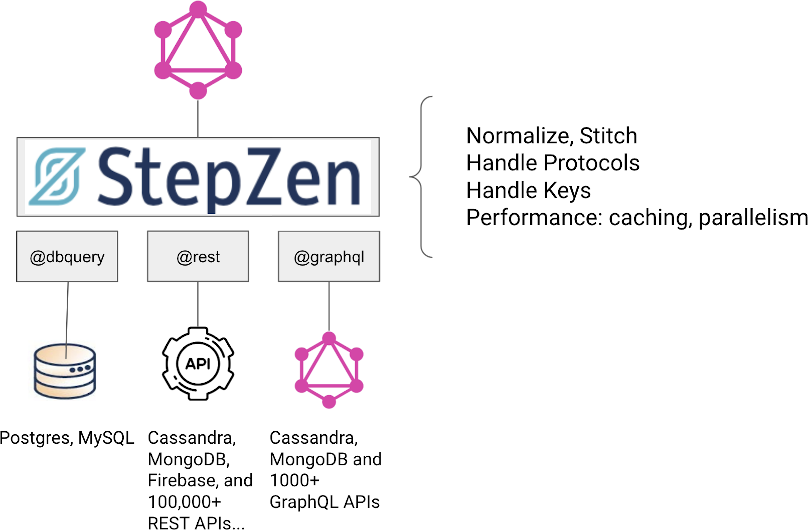
We offer multiple onroads to make this easier for you to implement:
- We introspect where possible (RDBMS, OpenAPI, GraphQL API), allowing us to automatically generate a schema based upon that introspection.
- We provide a large number of APIs with fixed schema (ex. weather, delivery) that allow you to connect to many popular APIs without writing any additional code yourself.
- You can craft your own schema directly and deploy that to StepZen.
Let's see how this works.
Building the GraphQL API
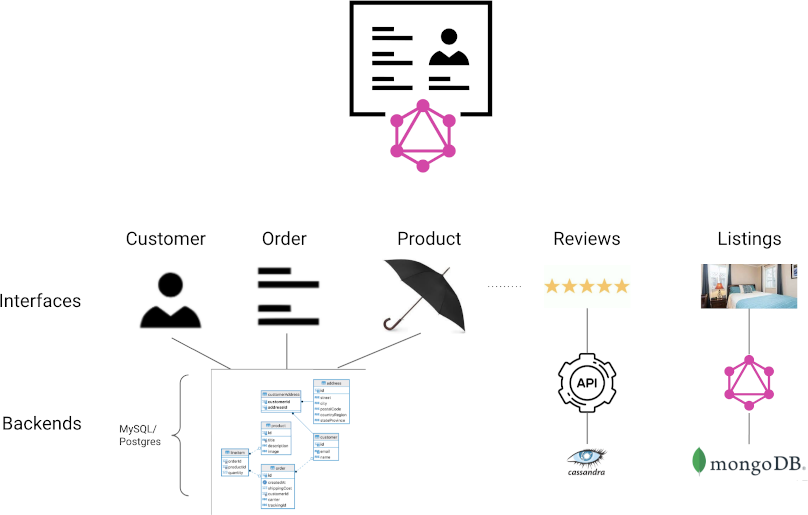
We're going to combine data from three different sources, which you can see in the diagram below.
Customer,OrderandProductwill all be coming from MySQLReviewswill be coming from Cassandra via RESTListingswill be coming from MongoDB via GraphQL
Let's look at the reviews first, which are stored in Cassandra. In this case, I've written a custom ProductReview type only has two properties, an ID and a list of reviews stored as JSON. The query interfaces are simple and use a REST endpoint for Cassandra and passes the correct parameters to it.
type ProductReview {
productId: ID!
reviews: JSON
}
type Query {
productReviews(productId: ID!): ProductReview
@rest(
endpoint: "https://$astraid.apps.astra.datastax.com/api/rest/v2/keyspaces/reviews/productreviews?where=%7B%22productId%22%3A%7B%22%24eq%22%3A$productId%7D%7D&page-size=20"
configuration: "astra_config"
resultroot: "data[]"
)
allProductReviews: [ProductReview]
@rest(
endpoint: "https://$astraid.apps.astra.datastax.com/api/rest/v1/keyspaces/reviews/tables/productreviews/rows?page-size=20"
configuration: "astra_config"
resultroot: "rows[]"
)
}
Now I want to connect these reviews with our product data that is stored in MySQL. In this case, I don't need to write out a custom schema. Instead, I will run the following StepZen CLI command from the command line:
stepzen import mysql
This will ask me a few questions so that it can introspect and configure the database:
? What is your host?
? What is your database name?
? What is the username?
? What is the password?
After that, it will generate a file based upon the database schema that uses the @dbquery directive to query the database and provide the data for the GraphQL types.
type Product {
}
That's all I need to do. I didn't write a single line of code and I have a schema that connects to my MySQL database. I can test out the schema I've created so far using the stepzen start --dashboard=local command, which will deploy my schema to StepZen and create a query editor allowing me to query that schema.
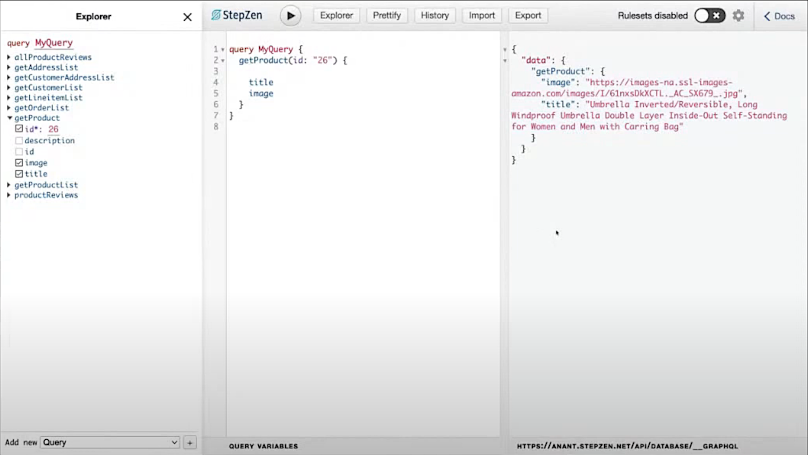
The default way to test your GraphQL endpoint is from the StepZen dashboard explorer. You can get a local GraphiQL IDE by running
stepzen startwith the--dashboard=localflag.
I'm getting reviews and products, but neither is connected. To do that, I need to use another custom StepZen directive, @materializer. This directive allows you to easily stitch types together. All I need to do is make a small change to the Product type that was generated to pull in reviews.
type Product {
description: String
id: Int!
image: String
title: String
productreviews: [ProductReview]
@materializer(
query: "productreviews"
arguments: [{ name: "productId", field: "id" }]
)
}
This will pass the productID parameter to the productreviews query on our ProductReview type and populate the productreviews property of Product with the result. We've now connected data coming from MySQL to data coming from Cassandra via a REST API with just a little bit of code!
What's Next
We didn't get to cover the entire schema. If you want to see how this all works and how I built out the rest of the schema, including the connection to MongoDB that was auto-generated using StepZen's GraphQL introspection, watch my recent webinar recording. You can also see the completed code in this GitHub repository. Nonetheless, I hope that this has illustrated how, using StepZen as a middleware, you can easily take data from your database as well as other backends and provide it to your frontend applications in the way that they want to consume it with minimal effort. So, why not give StepZen a try? I'm sure you'll make your backend developers and your frontend developers happy.


