How to Build a Headless CMS using Notion and StepZen

 Carlos Eberhardt
Carlos EberhardtIn this two part blog post I will walk you through a project I decided to take on the other day. I was doing some work in Notion when I realized that the editor was one of the nicer ones I’d used in an online tool. I wondered if I could use Notion as a headless CMS, and decided that would be a fun project to take on. I knew Notion had an API, but I didn’t know much about it. I decided I would try convert it to a GraphQL API using StepZen, and then to prove it would work as a headless CMS, I would build a blog site using the GraphQL API for content.
The Plan
With any project like this, I like to think about the layers of architecture, identify any unknowns in each layer, and then do some quick experimentation to make sure I’m not going to hit any big roadblocks. It’s similar to a spike in XP or Agile methodologies, but not necessarily an end-to-end solution. There are not too many layers in this one, really. I have Notion as a data store, StepZen as my API layer, and any number of blog engines to choose from. I hadn’t used Eleventy before, but it had been on my list of things to try, so I decided to start with that, and change the front end engine if I hit a wall. So, having a fairly good idea of my layers, I looked for unknowns. My first unknown was how I would get page content from Notion using their API. Next I’d need to make sure I could convert that into a usable GraphQL API with StepZen, and finally I would need to figure out how to get dynamic data using Eleventy. I wasn’t too worried about the third, because the community of developers around most blog engines is such a great resource I figured if it was possible, someone would have a tutorial on it (and I was right.. more on that in the second post of the series).
The Notion API
To explore the Notion API I logged into Notion and created a database to for my posts. If you want to try this yourself, Notion has free accounts and lots of help available: https://www.notion.so/help/guides/creating-a-database .
After getting my database set up and putting a few sample posts in it, I was ready to use the API. My first step was to search for “notion api” which landed me at the Notion Developers page. Reading their getting started section I learned I needed to create a Notion Integration, which would get me an API key. I followed their steps, not reading very closely, and got my API key. I hopped into the API reference to see how to pull up a list of pages, eventually landing on the search API: https://developers.notion.com/reference/post-search, but no matter how I called the search API I was getting an empty response. For example:
🐒➔ curl -H "Authorization: Bearer ******" https://api.notion.com/v1/search -H "Notion-Version: 2022-06-28" -X POST
{"object":"list","results":[],"next_cursor":null,"has_more":false,"type":"page_or_database","page_or_database":{}}%
I could see that the call was succeeding, I just couldn’t pull up any content. Going back and reading the getting started instructions a bit more closely, I realized I needed to connect my blog “database” to the Notion Integration I had created. That’s Step 2 of the Getting Started document.
It pays to slow down and read every so often! After connecting my integration to my blog database in Notion, I got the search API call to work, and jumped in to figuring out how to pull up the content of a page.
Notion Page Contents
The API reference pointed me to the Retrieve Block Children call in order to get the contents of a page, and here’s where I discovered my first challenge. The content of the page isn’t available directly as markdown, as I’d hoped, but in a collection of blocks, one for each section of text. And beyond that, a single block can be made up of multiple elements. For example, below I’ve pasted in a partial API response for the following sentence. A single line of text with multiple formats appears as multiple items:
"paragraph": {
"rich_text": [
{
"type": "text",
"text": {
"content": "A ",
"link": null
},
"annotations": {
"bold": false,
"italic": false,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": "A ",
"href": null
},
{
"type": "text",
"text": {
"content": "single line",
"link": null
},
"annotations": {
"bold": false,
"italic": false,
"strikethrough": false,
"underline": true,
"code": false,
"color": "default"
},
"plain_text": "single line",
"href": null
},
{
"type": "text",
"text": {
"content": " of text with ",
"link": null
},
"annotations": {
"bold": false,
"italic": false,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": " of text with ",
"href": null
},
{
"type": "text",
"text": {
"content": "multiple",
"link": null
},
"annotations": {
"bold": true,
"italic": false,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": "multiple",
"href": null
},
{
"type": "text",
"text": {
"content": " formats ",
"link": null
},
"annotations": {
"bold": false,
"italic": false,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": " formats ",
"href": null
},
{
"type": "text",
"text": {
"content": "appears",
"link": null
},
"annotations": {
"bold": true,
"italic": true,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": "appears",
"href": null
},
{
"type": "text",
"text": {
"content": " as multiple ",
"link": null
},
"annotations": {
"bold": false,
"italic": false,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": " as multiple ",
"href": null
},
{
"type": "text",
"text": {
"content": "items",
"link": null
},
"annotations": {
"bold": false,
"italic": true,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": "items",
"href": null
},
{
"type": "text",
"text": {
"content": ".",
"link": null
},
"annotations": {
"bold": false,
"italic": false,
"strikethrough": false,
"underline": false,
"code": false,
"color": "default"
},
"plain_text": ".",
"href": null
}
],
"color": "default"
}
},
So, while the API to retrieve content is straightforward, using that content is going to be a bit harder. I hit the search engines a bit more to make sure I hadn’t missed some way to pull markdown for a page using the API, but found nothing. So I had my first question answered. Can I get page content via an API call? Yes. Next question: can I convert that API into a usable content API using StepZen?
Converting with StepZen
While the response from the Notion API doesn’t have exactly what I want (which is the content of the page rendered as markdown), the response is fairly well structured JSON, so it should be possible to generate the markdown for each element of every block. StepZen supports an Open Source transformation language for JSON called JSONata (https://jsonata.org/) so my next challenge was to take this JSON response and generate the markdown for the page.
I created a page with a few different elements in it, made the API call to get the JSON for the page, and I hopped over to the JSONata exerciser (https://try.jsonata.org/) to see what I could accomplish. The first thing I did was create a function to find the distinct block types in the content:
(
$distinct($map(results, function($item) {
$item.type
}))
)
This resulted in the following:
[
"image",
"quote",
"paragraph",
"heading_2",
"bulleted_list_item",
"heading_3",
"numbered_list_item"
]
You can try this yourself at this link to the JSONata exerciser.
My plan was to iteratively process this JSON to create a new JSON response that contained the content of the page as markdown. I started by building functions that would return the markdown for each block in the page. For example, here’s a JSONata function that would take the page JSON and return a JSON structure with an array containing details about the H2 blocks and associated markdown representations:
(
$markdowntext := function($text, $annotations) {(
$out := $text.content;
$annotations.bold = true ? $out := $join(["**", $out, "**"]);
$annotations.italic = true ? $out := $join(["*", $out, "*"]);
$annotations.strikethrough = true ? $out := $join(["~~", $out, "~~"]);
$annotations.underline = true ? $out := $join(["<ins>", $out, "</ins>"]);
$annotations.code = true ? $out := $join(["`", $out, "`"]);
$text.link ? $join(["[", $out, "](", $text.link.url, ")"]) : $out;
)};
$richText := function($item) {(
$map($item, function($i) {(
$markdowntext($i.text, $i.annotations);
)})
)};
$makeObject := function($item, $content) {(
$content ? $c := $content : $c := "";
{"id": $item.id, "content": $c, "hasChildren": $item.has_children}
)};
$heading2 := function($item) {(
$join($append("## ", $richText($item.heading_2.rich_text)))
)};
$blocks := $map(results, function($item){
$item.type = "heading_2" ?
$makeObject($item, $heading2($item))
});
{
"blocks": $blocks
}
)
This function defines some helper functions for processing the Notion blocks. Many Notion blocks have richText elements which contain style hints, or annotations, for a section of text, so I built a function to process those. I also built a $markdowntext function to return a markdown-formatted string given some text and style hints. Finally, I built a function called $makeObject which takes a block and converts it into a new JSON object with the block id, content as markdown string, and a flag indicating if the block had child blocks.
Given a certain set of Notion blocks as JSON, the above function will output:
{
"blocks": [
{
"id": "66caf23d-bad9-49b2-bdad-195c4339d5e2",
"content": "## Ways to Check for Ripeness",
"hasChildren": false
},
{
"id": "0f502668-2b42-452d-9b89-13458bed56f0",
"content": "## The Best Way to Check",
"hasChildren": false
}
]
}
Since blocks can have children in Notion, I wanted to build in some capability to possibly process those child blocks. I didn’t plan on using it in this first iteration, but I wanted to explore it later so I left it in the transformation.
Now that I had a general framework built, I went about the process of creating new style elements in my sample blog post and creating the functions in JSONata to process them. When I had a good set of functions that would process the content from my samples, I modified the return output to include all of the markdown text of the blocks concatenated together. Here’s the final JSONata function:
(
$markdowntext := function($text, $annotations) {(
$out := $text.content;
$annotations.bold = true ? $out := $join(["**", $out, "**"]);
$annotations.italic = true ? $out := $join(["*", $out, "*"]);
$annotations.strikethrough = true ? $out := $join(["~~", $out, "~~"]);
$annotations.underline = true ? $out := $join(["<ins>", $out, "</ins>"]);
$annotations.code = true ? $out := $join(["`", $out, "`"]);
$text.link ? $join(["[", $out, "](", $text.link.url, ")"]) : $out;
)};
$markdowmimage := function($item) {(
$item.caption ?
$join([""]) :
$join([""])
)};
$richText := function($item) {(
$map($item, function($i) {(
$markdowntext($i.text, $i.annotations);
)})
)};
$makeObject := function($item, $content) {(
$content ? $c := $content : $c := "";
{"id": $item.id, "content": $c, "hasChildren": $item.has_children}
)};
$heading1 := function($item) {(
$join($append("# ", $richText($item.heading_1.rich_text)))
)};
$heading2 := function($item) {(
$join($append("## ", $richText($item.heading_2.rich_text)))
)};
$heading3 := function($item) {(
$join($append("### ", $richText($item.heading_3.rich_text)))
)};
$paragraph := function($item) {(
$join($richText($item.paragraph.rich_text))
)};
$quote := function($item) {(
$join($append("> ", $richText($item.quote.rich_text)))
)};
$code := function($item) {(
$join(["```", $item.code.language,"\n",$item.code.rich_text.plain_text,"\n","````"])
)};
$image := function($item) {(
$item.image.type = "file" ? "<!-- file image types are not supported -->" :
$item.image.type = "external" ? $markdowmimage($item.image)
)};
$numberedList := function($item) {(
$join($append("1. ", $richText($item.numbered_list_item.rich_text)))
)};
$bulletedList := function($item) {(
$join($append("- ", $richText($item.bulleted_list_item.rich_text)))
)};
$columnList := function($item) {(
$item.column_list.column_list
)};
$blocks := $map(results, function($item){
$item.type = "heading_1" ?
$makeObject($item,$heading1($item)) :
$item.type = "heading_2" ?
$makeObject($item, $heading2($item)) :
$item.type = "heading_3" ?
$makeObject($item, $heading3($item)) :
$item.type = "paragraph" ?
$makeObject($item, $paragraph($item)) :
$item.type = "quote" ?
$makeObject($item, $quote($item)) :
$item.type = "numbered_list_item" ?
$makeObject($item, $numberedList($item)) :
$item.type = "bulleted_list_item" ?
$makeObject($item, $bulletedList($item)) :
$item.type = "code" ?
$makeObject($item, $code($item)) :
$item.type = "image" ?
$makeObject($item, $image($item)) :
$item.type = "divider" ?
$makeObject($item, "---") :
$item.type = "column_list" ?
$makeObject($item, $columnList($item)):
$item
});
{
"blocks": $blocks,
"markdown":$join($blocks.content, "\n")
}
)
I’m sure there are opportunities in there for simplification and refactoring, but at this point I still had not proven out my entire plan. I could always come back to this once everything was working to see if i could make this function cleaner or simpler. But at this point I’d proven that I can get markdown text for a page from the Notion API, using JSONata to do some post-processing. If there are elements the function doesn’t yet handle, I can reason about adding a way to make it work, so I felt pretty good about getting everything working. The next step in my process was to wire up a StepZen GraphQL API on top of the Notion API, applying the JSONata function.
StepZen
The first step with StepZen was to create a schema to call the Notion API to get a block content and transform it using the JSONata formula I developed in the previous step. Since I was defining the output type in my formula, I didn’t really need to do any importing of anything into StepZen; I could simply generate the schema by hand. First I defined the type for the content:
"""
The Content and Block types are used to retrieve markdown content for a Page in Notion.
"""
type Content {
markdown: String
blocks: [Block]
}
type Block {
id: ID
hasChildren: Boolean
content: String
}
Next I defined the query to retrieve the content for a given block (page) id:
"""
Get block content as markdown for a block id (typically a page id)
"""
content(parentId: ID!): Content
@rest(
endpoint: "https://api.notion.com/v1/blocks/$parentId/children"
configuration: "notion"
headers: [
{ name: "Authorization", value: "Bearer $apikey;" }
{ name: "Notion-Version", value: "2022-06-28" }
]
transforms: [
{
editor: """
jsonata:
(
$markdowntext := function($text, $annotations) {(
$out := $text.content;
$annotations.bold = true ? $out := $join(["**", $out, "**"]);
$annotations.italic = true ? $out := $join(["*", $out, "*"]);
$annotations.strikethrough = true ? $out := $join(["~~", $out, "~~"]);
$annotations.underline = true ? $out := $join(["<ins>", $out, "</ins>"]);
$annotations.code = true ? $out := $join(["`", $out, "`"]);
$text.link ? $join(["[", $out, "](", $text.link.url, ")"]) : $out;
)};
$markdowmimage := function($item) {(
$item.caption ?
$join([""]) :
$join([""])
)};
$richText := function($item) {(
$map($item, function($i) {(
$markdowntext($i.text, $i.annotations);
)})
)};
$makeObject := function($item, $content) {(
$content ? $c := $content : $c := "";
{"id": $item.id, "content": $c, "hasChildren": $item.has_children}
)};
$heading1 := function($item) {(
$join($append("# ", $richText($item.heading_1.rich_text)))
)};
$heading2 := function($item) {(
$join($append("## ", $richText($item.heading_2.rich_text)))
)};
$heading3 := function($item) {(
$join($append("### ", $richText($item.heading_3.rich_text)))
)};
$paragraph := function($item) {(
$join($richText($item.paragraph.rich_text))
)};
$quote := function($item) {(
$join($append("> ", $richText($item.quote.rich_text)))
)};
$code := function($item) {(
$join(["```", $item.code.language,"\n",$item.code.rich_text.plain_text,"\n","````"])
)};
$image := function($item) {(
$item.image.type = "file" ? "<!-- file image types are not supported -->" :
$item.image.type = "external" ? $markdowmimage($item.image)
)};
$numberedList := function($item) {(
$join($append("1. ", $richText($item.numbered_list_item.rich_text)))
)};
$bulletedList := function($item) {(
$join($append("- ", $richText($item.bulleted_list_item.rich_text)))
)};
$columnList := function($item) {(
$item.column_list.column_list
)};
$blocks := $map(results, function($item){
$item.type = "heading_1" ?
$makeObject($item,$heading1($item)) :
$item.type = "heading_2" ?
$makeObject($item, $heading2($item)) :
$item.type = "heading_3" ?
$makeObject($item, $heading3($item)) :
$item.type = "paragraph" ?
$makeObject($item, $paragraph($item)) :
$item.type = "quote" ?
$makeObject($item, $quote($item)) :
$item.type = "numbered_list_item" ?
$makeObject($item, $numberedList($item)) :
$item.type = "bulleted_list_item" ?
$makeObject($item, $bulletedList($item)) :
$item.type = "code" ?
$makeObject($item, $code($item)) :
$item.type = "image" ?
$makeObject($item, $image($item)) :
$item.type = "divider" ?
$makeObject($item, "---") :
$item.type = "column_list" ?
$makeObject($item, $columnList($item)):
$item
});
{
"blocks": $blocks,
"markdown":$join($blocks.content, "\n")
}
)
"""
}
]
)
While this is large, it’s primarily due to the JSONata formula we’re applying in the @rest directive’s transforms argument. The rest of the configuration is very straightforward. We set the endpoint for the Notion API, including the query argument parentId in the URL path. And we configure the headers, including Authorization, which comes from our configuration file, configuration: "notion".
Deploying this schema to my StepZen account, I’m now able to run a query and retrieve the markdown content for a given page in my Notion blog database:
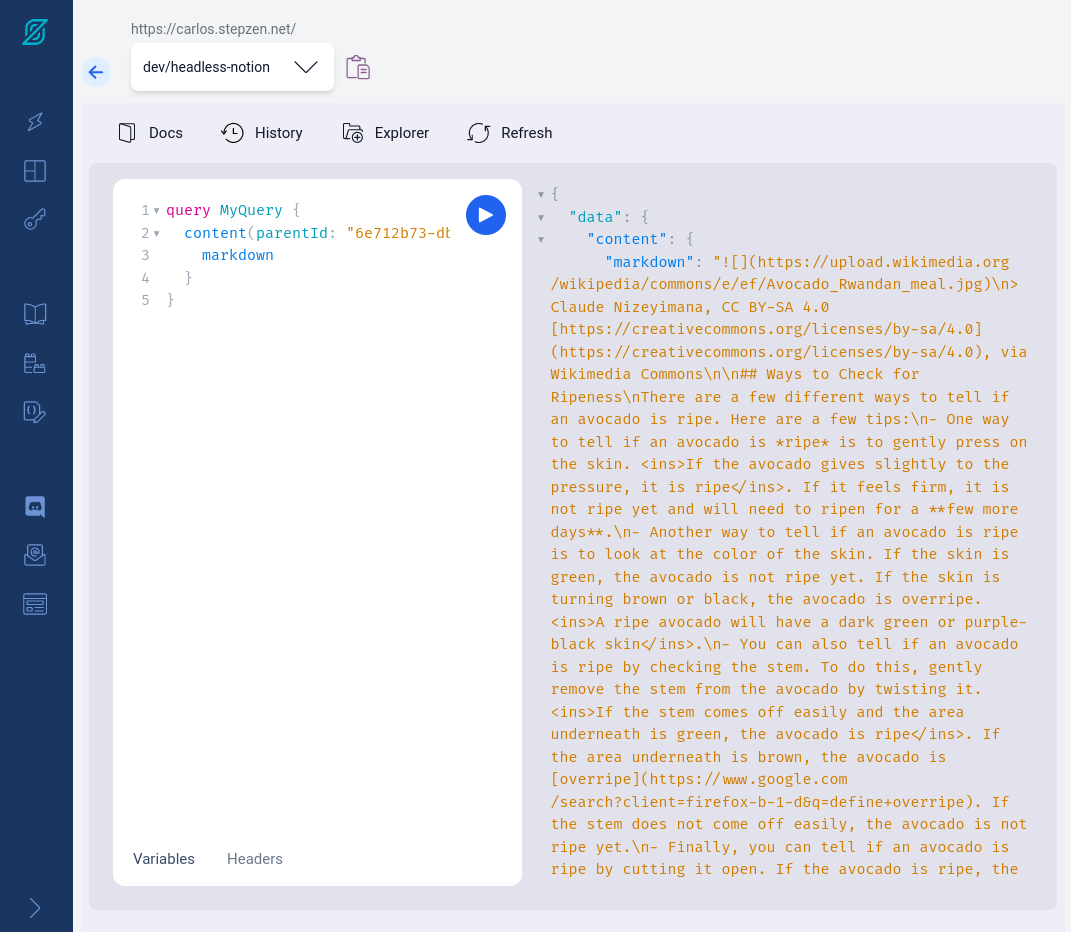
Screenshot of GraphQL Query and Response
Finally, I had a GraphQL API that would give me the markdown content for a given page id in my Notion blog database. At this point I felt I had accomplished the most critical parts of the “spike” I wanted to build. The hardest part was probably over! It was time to take a quick stretch get a drink of water. After my stretch I started work on additional API capabilities that would turn this API into a useful headless CMS API.
Filling out the Missing API Functonality
In order to use this API as a CMS API for my blog, I needed to have a way to retrieve the front matter for each post; things like the title, author, date, tags, etc. I also needed to be able to get a list of posts to publish. I’d added a checkbox field to my pages called “publish” which I wanted to use to indicate if a page is ready to be published, and I figured I could search for pages with that flag set.
For the front matter details, I started investigating the Retrieve a Page API for front matter details, and it would have worked, but while I was testing that API I looked into the API for querying the database and discovered that API would provide me with all the front matter for the pages as well as a way to get a list of pages given a specific criteria, e.g. all the published posts. To use this API with my StepZen schema I took advantage of the StepZen CLI’s import command. Import will introspect various systems, including REST APIs, and automatically generate a schema for what it finds:
🐒➔ stepzen import curl -H "Authorization: Bearer $NOTIONKEY" -H "Notion-Version: 2022-06-28" "https://api.notion.com/v1/databases/$DBID/query" -X POST
Running this import command will generate all the types I need, but I still have a little work to do to set up the correct search I want to run. The Notion API supports pagination, so I should enable that with my GraphQL API, and I should also configure the query field to support filtering and sorting using Notion’s API capabilities. Luckily, doing all this in StepZen is really fairly easy. Here’s my schema for the pages query:
"""
Get pages given optional filter and sort criteria. Defaults to first 100 pages.
"""
pages(
first: Int! = 100
after: String
""" A valid Notion filter. See https://developers.notion.com/reference/post-database-query-filter """
filter: JSON
""" A valid Notion sort. See https://developers.notion.com/reference/post-database-query-sort """
sorts: JSON
): PageConnection
@rest(
endpoint: "https://api.notion.com/v1/databases/$dbid;/query"
method: POST
headers: [
{ name: "authorization", value: "Bearer $apikey;" }
{ name: "notion-version", value: "2022-06-28" }
]
arguments: [{name: "page_size", argument: "first"}{name: "start_cursor", argument: "after"}]
pagination: { type: NEXT_CURSOR
setters: [{field:"nextCursor", path:"next_cursor"}]}
resultroot: "results[]"
configuration: "notion"
)
This query allows passing in JSON objects for Notion’s sorting and filtering capabilities, and converts Notion’s REST paging style to GraphQL pagination. After deploying my schema, I can now run queries to retrieve a list of my blog posts, for example, published posts tagged with the topic “Rust”:
query q($filter: JSON) {
pages(filter: $filter) {
edges {
node {
properties {
Name {
title {
plain_text
}
}
}
}
}
}
}
with variables:
{
"filter": {
"and": [
{
"property": "Publish",
"checkbox": {
"equals": true
}
},
{
"property": "Tags",
"multi_select": {
"contains": "Rust"
}
}
]
}
}
And the response will look like:
{
"data": {
"pages": {
"edges": [
{
"node": {
"properties": {
"Name": {
"title": [
{
"plain_text": "How to Call a GraphQL API Using Rust"
}
]
}
}
}
},
{
"node": {
"properties": {
"Name": {
"title": [
{
"plain_text": "How to Create a Command Line Application in Rust"
}
]
}
}
}
}
]
}
}
}
So now I have a way to query my blog database for any set of posts I want to use on my blog. In fact, I go one step further. Instead of querying for a list of posts and then querying for content, I can use StepZen’s @materializer directive to link types. Then I can make a single GraphQL query to retrieve all the information I need for my blog. Linking types in StepZen is very easy. It looks like this:
extend type Page {
content: Content
@materializer(
query: "content"
arguments: [{ name: "parentId", field: "id" }]
)
}
I simply extend the type Page and add a field I named content. Then I decorate that field with the @materializer directive, providing arguments for the query to run, and any argument mapping if necessary. Now I can modify my earlier query to ask for the content field:
query q($filter: JSON) {
pages(filter: $filter) {
edges {
node {
properties {
Name {
title {
plain_text
}
}
}
content {
markdown
}
}
}
}
}
And the response gives me the title and content for each matching page:
{
"data": {
"pages": {
"edges": [
{
"node": {
"properties": {
"Name": {
"title": [
{
"plain_text": "How to Call a GraphQL API Using Rust"
}
]
}
},
"content": {
"markdown": "To write a function to call a GraphQL API in Rust, you can use the `reqwest` crate to make HTTP requests and the `serde_json` crate to parse and serialize JSON data. Here's an example of how you might write a function to call a GraphQL API:\n```rust\nuse reqwest::{Client, Error};\nuse serde_json::{json, Value};\n\n// Function to call a GraphQL API\nasync fn call_graphql_api(query: &str) -> Result<Value, Error> {\n // Create a new HTTP client\n let client = Client::new();\n\n // Set up the request parameters\n let request_body = json!({\n \"query\": query,\n });\n let request_url = \"https://api.example.com/graphql\";\n\n // Send the request and get the response\n let response = client\n .post(request_url)\n .json(&request_body)\n .send()\n .await?\n .json()\n .await?;\n\n // Return the response body\n Ok(response)\n}\n````\n\nThis function takes a string representing the GraphQL query as an argument, constructs an HTTP request with the `reqwest` crate, sends the request to the specified URL, and returns the JSON response as a `serde_json::Value`.\nYou can then use this function to call a GraphQL API by passing a query string to it, like this:\n```rust\nlet query = \"{\n user(id: 1) {\n name\n }\n}\";\nlet response = call_graphql_api(query).await;\n````\nThis code will call the GraphQL API with the given query and return the response as a `serde_json::Value`. You can then use the methods provided by the `serde_json` crate to parse and extract the data you need from the response."
}
}
},
{
"node": {
"properties": {
"Name": {
"title": [
{
"plain_text": "How to Create a Command Line Application in Rust"
}
]
}
},
"content": {
"markdown": "To create a command line app in Rust, you can use the `std::env` module to parse command line arguments. Here's an example of how you might do this:\n```rust\nuse std::env;\n\nfn main() {\n // Get the command line arguments\n let args: Vec<String> = env::args().collect();\n\n // Check for the required number of arguments\n if args.len() != 3 {\n println!(\"Usage: {} <input_file> <output_file>\", args[0]);\n return;\n }\n\n // Get the input and output file paths\n let input_file = &args[1];\n let output_file = &args[2];\n\n // Open the input file\n let input = std::fs::read_to_string(input_file).expect(\"Failed to read input file\");\n\n // Perform some action on the input, such as parsing or transforming it\n\n // Write the output to the output file\n std::fs::write(output_file, output).expect(\"Failed to write to output file\");\n}\n````\nThis code will parse the command line arguments and expect two arguments: the input file path and the output file path. It will then read the input from the specified file, perform some action on it, and write the output to the specified output file.\nOf course, this is just one way to create a command line app in Rust. You can also use libraries like `clap`\n to make it easier to parse and validate command line arguments."
}
}
}
]
}
}
}
For my blog solution, here’s an example of the query I use to retrieve all publish blogs, their front matter, and content:
query q($filter: JSON, $sort: JSON) {
pages(filter: $filter, sort: $sort) {
pageInfo {
hasNextPage
endCursor
}
edges {
node {
last_edited_time
properties {
Name {
title {
plain_text
}
}
Tags {
multi_select {
name
}
}
Author {
people {
name
avatar_url
}
}
}
content {
markdown
}
}
}
}
}
Now I have a pretty capable GraphQL API built on top of Notion. I can search for pages, control sort order and pagination, and retrieve all the necessary fields including content as markdown with a single API request!
To try this with your own StepZen and Notion accounts, grab the repo here https://github.com/stepzen-dev/headless-notion-cms and give it a whirl. Drop into our Discord if you have any questions.
In the next part of this series, we’ll build a blog using this new CMS API, and publish it on the web.


