Improving the Development Experience with GraphQL

 Leonardo Losoviz
Leonardo LosovizIn my previous article, How different are REST and GraphQL after all?, I argued that REST and GraphQL are not that different, so that using either API will help us achieve our goals, and we could decide which API to use on a project-by-project basis.
Having said that, though, there are reasons why we may want to choose GraphQL. One such reason is GraphQL's better development experience than REST's, involving:
- Faster iteration cycles to integrate the API with the application.
- Better communication among team members.
- Reduced effort in writing documentation.
In this article, I'll go over why I find GraphQL a better fit than REST for applications with fast-paced iteration cycles, and having many team members.
Fast iteration cycles when building our applications
Because of the rigid nature of a REST endpoint (where what data is returned is set in advance), if we need to access data that is not already provided by the endpoint, then a new endpoint must be created. When doing so, we may want to evaluate the other potential new features for the application, so as to avoid having to create new, unnecessary endpoints down the road.
This process may become a hurdle, shifting our goal in the short term. Our intention is to code a new feature, yet we had to shift our focus to something entirely different: evaluating how the data needs for the new feature are aligned with the data needs from other features, somewhere else in the application, possibly handled by other developers.
As a result, we are diverting our attention from our immediate goal, slowing down our progress.
GraphQL doesn't suffer from this inconvenience, because the returned data is not fixed. We can simply update the query to fetch the data required for the new feature, without having to inconvenience other developers, or make plans in advance. As a result, the development cycle is faster, and we can achieve more in less time.
Now, this is actually a half-truth: This situation applies as long as the field resolver providing the required data already exists!
If the field resolver hasn't been coded yet, then we may face a similar hurdle as with REST – coordinating with other team members to make sure that the new field resolver can also satisfy the needs from other new features, as much as possible. This is necessary to avoid having to create new, unnecessary field resolvers down the road.
Hence, we can expect GraphQL to produce faster development cycles than with REST, but this is most evident when the application is mature, having had its data model mapped via field resolvers.
Improving communication within the team
GraphQL provides a few advantages over REST, when several team members (whether techies or not) need to collaborate to create an API, and integrate it within the application.
SDL as a common language for collaboration
GraphQL provides the Schema Definition Language, or SDL, to document the creation of the schema. Because SDL is a language, we can use it to communicate our intentions when creating an API.
For instance, this piece of SDL describes a new type Client for the GraphQL schema:
type Client {
id: ID
name: String!
surname: String
company: Company
roles: [Role!]!
}
This piece of code makes it clear which properties are assigned to our clients in the application. The GraphQL schema maps the data model, via type Client with fields id, name (which is mandatory), surname (which is optional), company (whose type, Company, must also be defined in the schema), and roles (which is an array of an enum type called Role).
SDL is very understandable. With some training, non-coders should also be able to comprehend it, so it can become a cross-department tool for collaboration.
We can also base our API on some documented standard using REST, such as OpenAPI. However this is more technical, which means it is more difficult to understand the data model quickly or have non-coders be able to use it.
Clients to visualize the data model
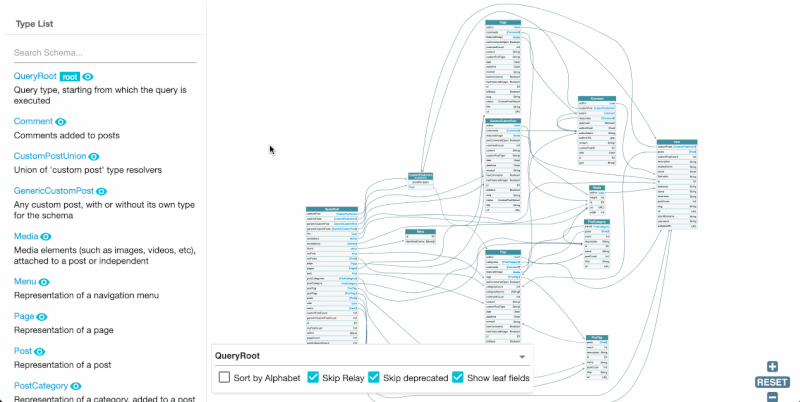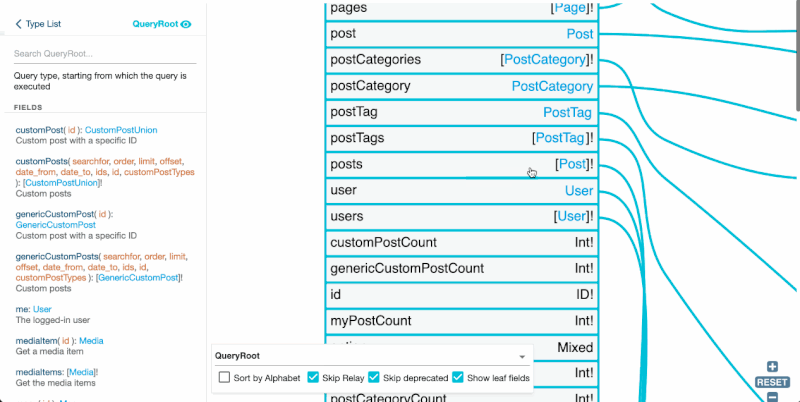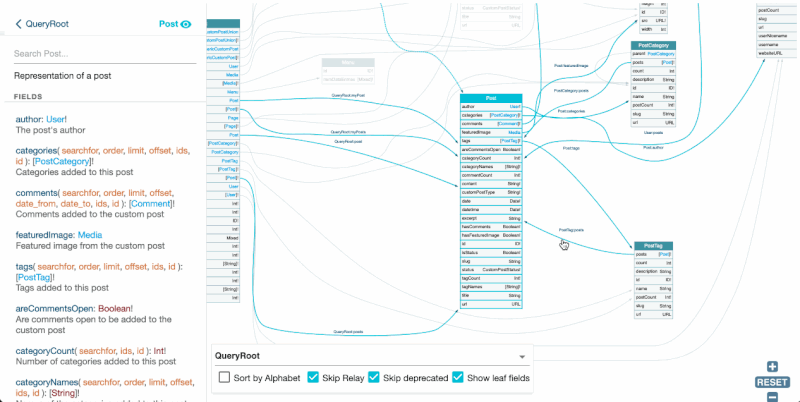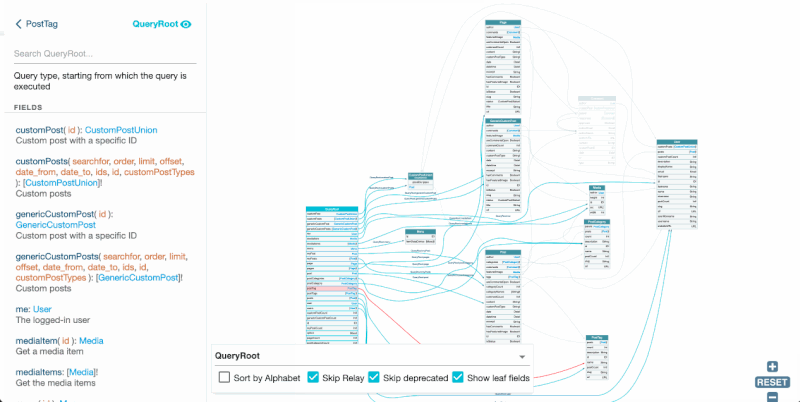
There are several open source clients for GraphQL which help us comprehend the GraphQL schema in a visual manner.
In a previous article, A Visual Guide to GraphiQL and GraphQL Voyager, we learnt about two such clients: GraphiQL and GraphQL Voyager.
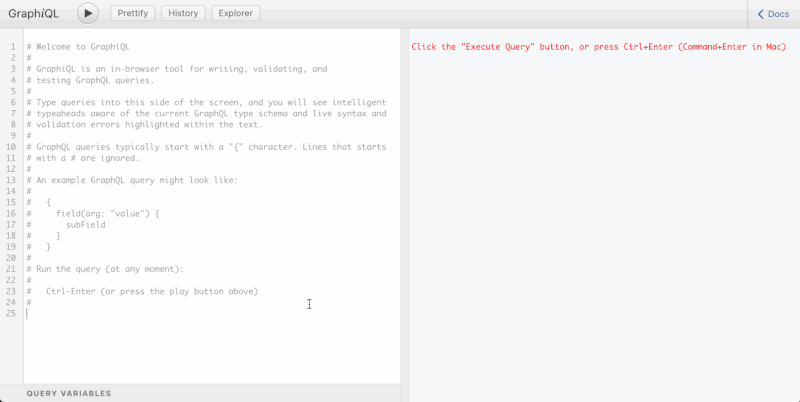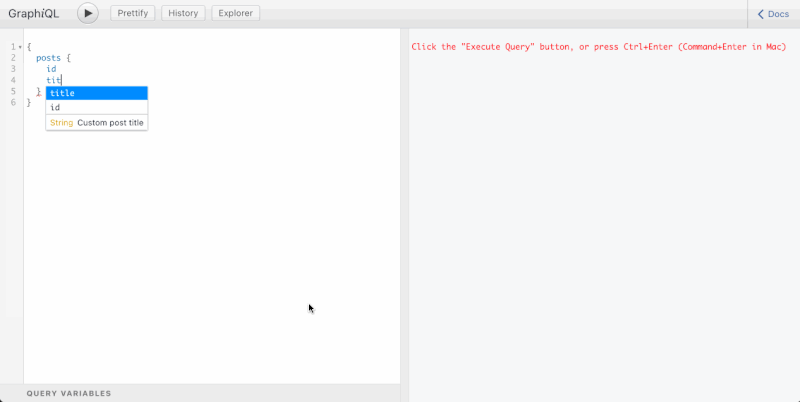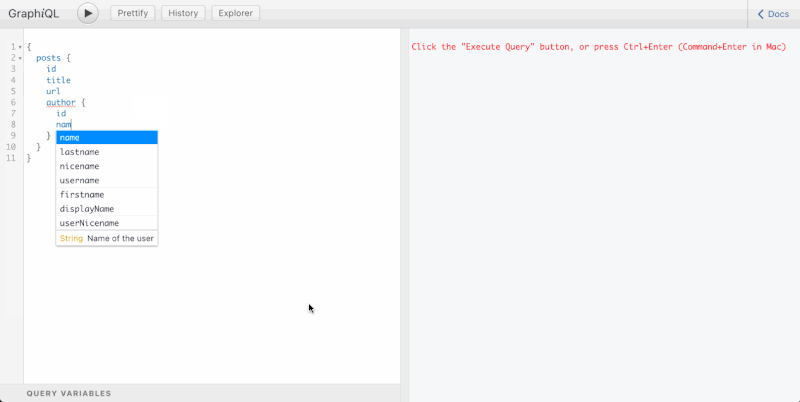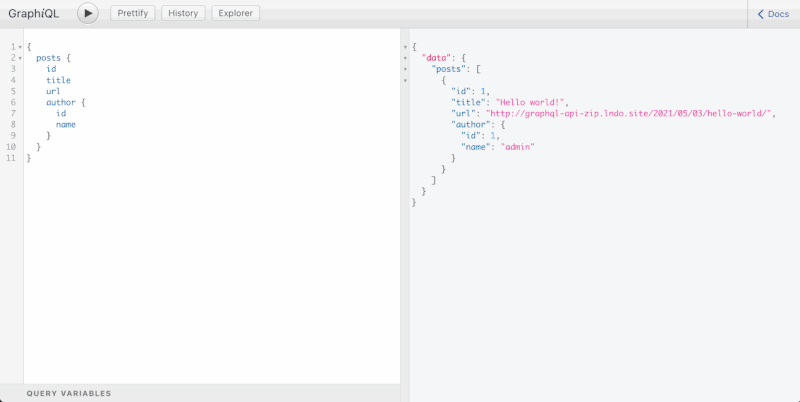
GraphiQL is an IDE for composing GraphQL queries, executing them against the endpoint, and visualizing the response:
GraphQL Voyager is a tool to visualize the GraphQL schema, which excels and displaying how every element relates to each other:
To date, I haven't seen any similar client for REST.
These tools help make an API tangible: We can switch from using words to describe it, to using images to visualize it. This makes it easier for everyone in the team to have the same understanding of the data model being discussed.
Reducing the effort to document the API
One of the biggest issues with REST is that it is mandatory to document each and every endpoint, specifying what fields it contains and what parameters it can receive, when and how it should be accessed, and what response code we will get. Otherwise, we risk having our clients/users not be able to use our REST API's endpoints.
There are tools which can help automatically produce documentation from the source code, such as Swagger UI, which produces documentation for OpenAPI. However, we must deploy the documentation on a separate site (such as api.mysite.com), and keep it up-to-date.
Providing comprehensive documentation is an effort which, if not handled properly, can easily become burdensome. Eventually, developers may forget about it, or find it bureaucratic to deal with, and eventually skip documenting endpoints, slowly but surely degrading the value from the API.
In GraphQL, we must also document APIs. However, documenting APIs is implicit on GraphQL itself. In one way, the GraphQL schema is already a documentation of itself. (Please notice: GraphQL reduces the effort to document the API, it doesn't remove it! If you have read elsewhere that GraphQL is documentation-less, well, that's not true.)
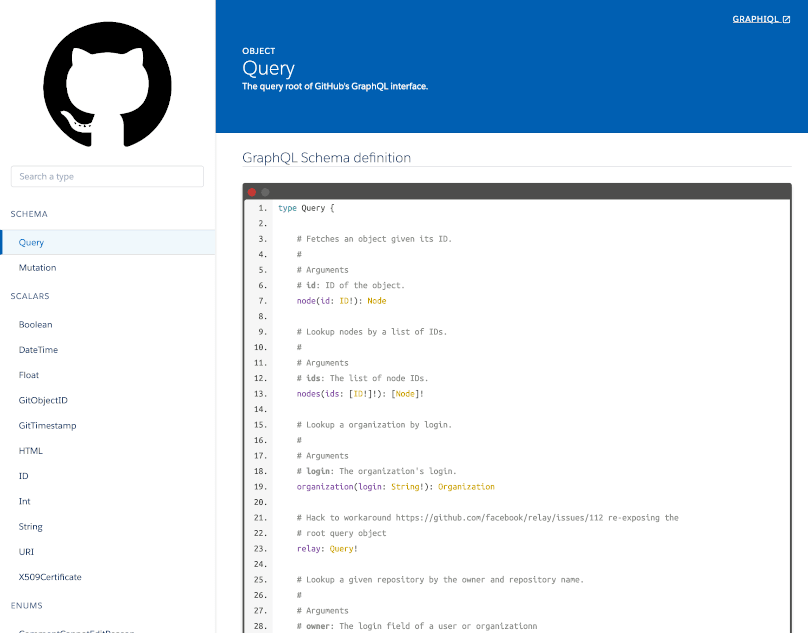
The documentation for a GraphQL API can already be browsed when visualizing the GraphQL schema, from a plethora of clients via introspection, including the ones we saw earlier on, GraphiQL and GraphQL Voyager. Hence, we do not need to deploy a separate documentation website.
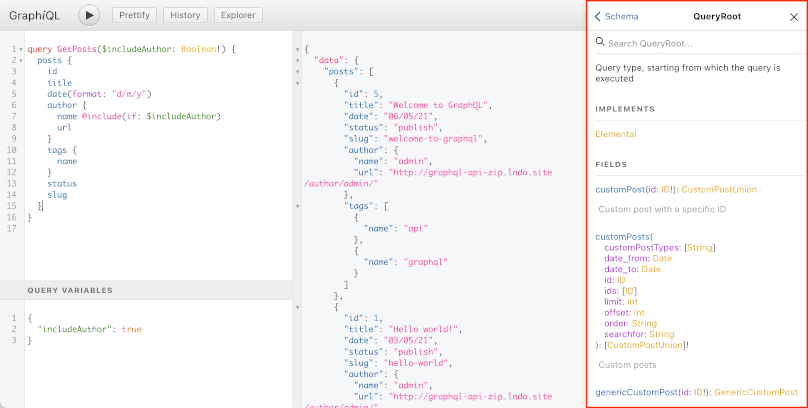
This is possible because the GraphQL schema contains a description of each field, and the schema is strongly typed (i.e. fields and field arguments must indicate their type). Combining the field's name, description and type will already illustrate the field's purpose, and how it must be used.
If we still want to create a separate documentation website api.mysite.com, we still can. There are documentation generators too, automatically producing documentation from the GraphQL schema, such as Graphdoc and SpectaQL.
Conclusion
There is not fixed rule on what technology we must use for every project. Different stacks provide different benefits, and we should decide which stack is most suitable for each project.
When should we use GraphQL? This article described the one area where using GraphQL is compelling: when we value a good development experience. This involves being able to manage our API efficiently, improving the communication with team members, reducing the effort to documentat the API, and speeding up the time to have our code go from development to production.


