Learn To Love Your Jamstack BFF

 Brian Rinaldi
Brian RinaldiThis Valentine's Day, don't forget about your BFF. Sure, your BFF may make your life difficult sometimes, but you still need your BFF. No, I'm not talking about your best friend, I'm talking about the BFF architectural pattern. What's BFF? Let's start with a quick summary.
Back in 2015, Phil Calçado introduced an architectural pattern called Backends for Frontends or BFF that had been used at SoundCloud. That same year Sam Newman defined the pattern as well.
The BFF pattern grew out of the need to support multiple user interfaces with differing needs, particularly mobile interfaces that had a number of constraints. The monolithic API had become a bottleneck to development and couldn't always serve the needs of the multiple user interfaces easily. So, rather than have each frontend call a single monolithic API backend, each frontend would implement their own API layer that would leverage an application service layer that then called the underlying microservices. This BFF would be maintained by the frontend application team, thus freeing them of the constraints of waiting on changes to the underlying API to iterate on the UI, while also allowing them to refine and structure the API to meet the specific needs of their UI. For example, the mobile UI might require less data than a desktop UI and reducing the payload of an API call could improve the performance of the mobile app.
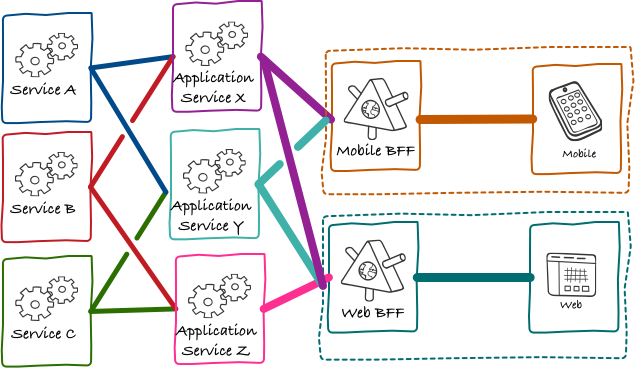 _Source: The Back-end for Front-end Pattern (BFF)
_Source: The Back-end for Front-end Pattern (BFF)
What Does BFF Have To Do With Jamstack?
This pattern might not seem entirely relevant to the Jamstack, which frequently relies heavily upon leveraging specialized microservices along with third-party services and APIs. Especially for complex applications, the Jamstack approach can result in some complications:
- Frequently, to use an API within the frontend UI, an intermediary layer needs to be created to protect API key access and limit what parts of the underlying API can be called and from where. This is usually built as a serverless function, which hides the key and exposes specific API functionality. (For a look at how you can secure these endpoints, read our recent blog post.)
- Combining multiple microservices, third-party services and APIs can become incredibly complex and hard to maintain. Thus, the intermediary layer can become a place where the various microservice and API calls are combined into a format that is easily consumed by the frontend.
As you can see, while the code may exist in one or more serverless functions, in the scenario I laid out across the two bullet points, we've effectively created a BFF for the Jamstack app. This is something that Jay Freestone spoke about in his recent Front-end predictions for 2021:
Over the last few years, the widespread use of micro-services has necessitated patterns such as Backend For Frontend (BFF), which introduces an intermediary between each client and the APIs which service it.
This is particularly relevant in 2021 given the current interest in the JAMStack, which, at its most complex, suffers under the weight of its service dependencies. The answer to ‘how do I federate my APIs’ will be, amusingly: build one.
Now, I personally take Jay Freestone's critiques of Jamstack with a grain of salt. He's been very open about being a Jamstack skeptic, even if his criticisms seem to reflect a very narrow (and overly Netlify-centric) view of the Jamstack ecosystem. That being said, he's right that this BFF pattern can often apply to the Jamstack and it presents a number of problems in that they can be difficult to build and maintain.
Does GraphQL Solve the BFF Problem?
As Bowei Han notes, two of the key benefits of the BFF pattern are the ability to adjust payload size and request frequency reduction while also providing a single resource server for the frontend to call. GraphQL offers advantages over RESTful APIs that would seem to address these issues:
- The ability to get only the data you need. A GraphQL query allows you to request only the data you need for your frontend, unlike REST, which sends the entire payload regardless of whether it is needed. For example, if I only need a user's name to display, I can request and receive only that single piece of data.
- The ability to get all the data you need in a single request. There's no need to call multiple endpoints and stitch together the data within a GraphQL API because it allows you to request all the data you require across all the available types in in a single query. For example, I don't need to call the user endpoint to get user data and then the orders endpoint to get their orders. I can instead get a user with their orders in a single call.
- GraphQL provides a single resource server to call. Unlike REST, there aren't multiple endpoints but a single GraphQL endpoint. There are even tools such as schema stitching or federation available to combine multiple GraphQL endpoints.
But GraphQL doesn't directly solve the traditional BFF issue nor the "Jamstack BFF." As Phil Calçado mentions in "Some thoughts on GraphQL vs. BFF":
The defining characteristic of a BFF is that the API used by a client application is part of said application, owned by the same team that owns it, and it is not meant to be used by any other applications or clients.
He explains:
The first friction point is that it is hard for me to believe that you can combine the needs of many different applications, owned by different teams, with different users and use cases, in a single schema.
By nature, the GraphQL API isn't specific to the needs of the frontend application consuming it and we can end up with some of the same difficulties that the BFF pattern was trying solve such as the difficulty iterating on an API that has to serve multiple frontends. Or, as Andy Roberts put it in "The Evolution of GraphQL at Scale":
The more teams there are making changes to it, the harder it is to release change, and, before you know it, the dream becomes a nightmare and our monolithic GraphQL API becomes a hated beast.
The solution he recommends is to make a GraphQL schema per experience, essentially mirroring the BFF pattern, and leveraging tools like Apollo Federation to combine multiple schemas as needed per experience to reduce code duplication. The issue, of course, is that neither creating and maintaining multiple GraphQL APIs nor using federation is trivial. Plus, for the Jamstack developer, we also haven't necessarily negated the need for the intermediary layer to authenticate with the GraphQL API and pass through queries.
Towards Solving This Problem for the Jamstack
We've given these issues a lot of thought at StepZen, particularly as they relate to the Jamstack. We believe in the benefits of adopting GraphQL to reduce unecessary payload size, reduce the number of requests needed to get data, and provide a single endpoint for your application data. But we also realize this can come with a number of burdens, particularly for the frontend developer.
The biggest problem is that it is time consuming and difficult to spin up new GraphQL APIs, so the idea that you could create one specific to a frontend can be a major burden. It's also not necessarily common for a frontend team to have the expertise needed to build GraphQL APIs. Plus, having to still create the intermediary layer to handle things like keys and access control only increases this burden.
We're not the only company who sees these problems and is tackling them, but we think we have a unique solution to them that makes it easy to spin up new GraphQL APIs, even while combining multiple backend sources (including databases and APIs). This allows frontend developers to create the API they need, even stitching together disparate sources of data. We're also working on solutions to address the need for the intermediary layer for handling keys, so that you'll be able to call your GraphQL API directly from the frontend without writing a serverless function to manage keys and access.
In the end, the BFF pattern solves real problems for developers, but it comes with burdens. Rather than revert to the monolith, if we can mitigate or eliminate those burdens, we can get the benefit of BFF without the pain, and learn to love our BFF again.


