A New Architecture for APIs

 Anant Jhingran
Anant JhingranHaving been in the API space for the last decade (at Apigee, Google, and now StepZen), and having done databases for two decades prior (at IBM and during my dissertation at Berkeley), I can safely say that there are two tricks that databases have done well, that will revolutionize how APIs are built and managed.
The first is that databases operate declaratively. That means you tell the database what to do, not how to do it. You follow that principle whether you are creating data or querying for it. APIs, on the other hand, have mostly been created programmatically.
Second, equally importantly, many databases know how to federate, meaning that if your data is scattered across two database systems, then one can execute a query against both as if it was coming from one. The query that you submit is scattered to multiple backend databases, and the results are gathered to present as if they were coming from one centralized system.
In this paper, we will address the latter, we have previously written articles about the former.
Federation of APIs
I had first heard this concept in hearing how Netflix talked about their API tier, in particular from Dan Jacobsen, who is now at the New York Times. Netflix had “domain APIs” that reflected how backends viewed and surfaced their data, and they had “experience APIs” that reflected how applications wanted to access the data. Each experience API made the right call to a set of domain APIs (scattered), and then combined the results (gathered) into one.
But scattering/gathering is not easy. In traditional APIs, it is hardwired into the way each API is built. If the experience API needed some more data, someone would go in and program that API to now scatter to another backend. If the backend API changed its implementation, someone would go in and reprogram the experience API. Errors from backends? Program. Perform issues? Program (add cache), etc., etc.
Furthermore, why do two levels, and does only two levels make sense? If you look at the World Wide Web, it is an interconnection of pages, grouped together into sites, grouped together into domains, etc. The structure of interconnectivity (href) is the same — and it allows for arbitrary complex relationships to be formed.
This needs to be the new world of APIs. However, for this world to form, there is one more fundamental shift that needs to happen. Scattering and gathering, when each backend produces arbitrary structures is almost impossible. There has to be a “standardization” of some form. And that standardization is GraphQL.
GraphQL, which stands for Graph Query Language, has two wonderful features.
- It allows for data to be stitched together:
{
customer (email: “john.doe@example.com”) {
orders {
status
}
}
}
returning customer and order data in one query, just like a federated database query.
- It returns the data in exactly the shape of the request. No more, no less. Now imagine a graph of GraphQL APIs:
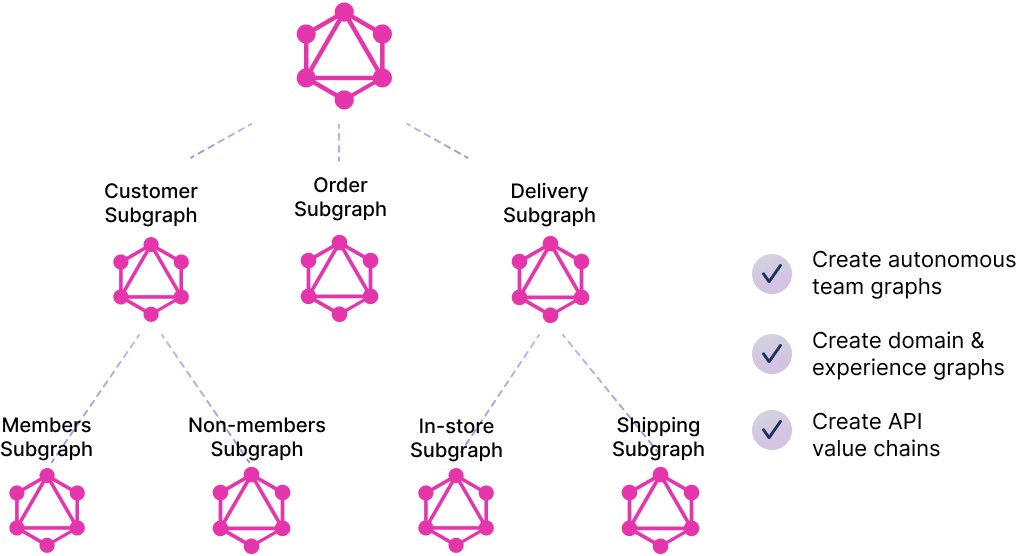
A GraphQL query at any one level can be scattered to the next-level subgraphs. The responses from them are in the exact shape of the subgraph subqueries that were sent to them. Gathering (stitching) them is trivial, there are no shapes to wrestle with, no logic to write. And this can continue on down.
As you can see, this is an entirely new API architecture. It is a federated graph of APIs, and can be used to build a big supergraph — or a single graph of graphs — and many smaller graphs-of-graphs, which can be scoped at whatever is the right structure for an organization. It is a very clean, easy concept. And it is the future.
However, that is not all. This architecture has some enormous positive implications on performance, governance and multicloud.
Performance
By federating and sending GraphQL subqueries down, you are not shipping unnecessary data up and down the supergraph. In database terms, this is called pushdown — you are letting each subsystem do the most it can, and only send the results of the computation back for the gather stage. This is the difference between computing a member’s total order amount by fetching all the orders and sending it to the customer subgraph (and letting it compute the total), vs. computing the total in the member’s subgraph and only sending the total to the customer subgraph. Good GraphQL systems understand what each subgraph can do, and try to do maximal pushdowns. In traditional API architectures, such knowledge has to be hardwired into the APIs that are further up the chain.
Governance
With this federation model, data does not leave the subgraph unless it has to. Imagine that you have an EU subgraph and a US subgraph. The scatter phase ensures that the EU subgraph is asked for something in its domain, and it can decide what data it can send upstream. Queries like “what is the total amount for a customer” can return the total amount, without violating any privacy issues or leaking specific order data. Or the subgraph can decide to obfuscate some data to preserve privacy.
In addition to the privacy issues, a federated model is just better for governance. Each team decides what its subgraph looks like. It can have a more detailed subgraph for internal use and expose fewer capabilities upstream. Of course, since the data returned has to make sense, it does not preclude the need for some lightweight governance across the subgraphs, but that is much less than what it would be if the whole thing was one tangled mess of programming logic.
Multicloud
Imagine if some of your services were on Google Cloud and some on AWS and some on-premises. You would want to manage them for governance and for performance, separately. In that world, this federated API structure is the only way to go.
Summary
APIs are great. However, API architectures have not evolved. With GraphQL, a new way of forming a graph of graphs is emerging. This architecture leads to a simpler design, better performance, simpler governance and graceful migration to the cloud. It is the way forward.
This article was originally published in The New Stack: 


