A New Workflow for API Mash-Ups: Postman, StepZen, and the YouTube Data API

 Joey Anuff
Joey AnuffThe code for this project (YouTube schema and StepZen configs) can be found in Joey’s stepzen-youtube-data-api repo on GitHub.
If you could sort YouTube comments like Reddit comments—linearly, quantitatively—would that make them any easier to digest? I recall wondering that during my very first sessions with the YouTube Data API Explorer—in retrospect, formative moments for me as a web developer. The idea that some random developer could reorder YouTube’s whole comment section on a whim was a big part of why I finally started writing code. But lately I’ve been asking myself: if the freedom to tap into big public APIs was such a strong motivator, why have I built so few API-driven front-ends in the half-decade since I learned how?
Had I not recently stumbled into this workflow, it might never have occurred to me that my API hang-ups weren't entirely personal. But thanks to the paired utility of two development tools–StepZen, an API-mixing schema generator, paired with Postman, the familiar API testing suite–it’s suddenly seeming plausible to iterate custom API mash-ups, far quicker than I’d ever imagined. And after working with these tools, I can more readily see why, absent a closely supportive toolchain, I’d avoided multi-step or multi-API orchestrations for so long. Even with the right tools, it’s tricky!
YouTube’s comment sort reordered as numerical ranking
Consider the GraphQL schema in the linked repo. Written to retrieve the most liked and replied comments of a given YouTube channel, it leans upon some of StepZen’s most timely features: sequencing API calls by way of their @sequence and @materializer directives, and JSON simplification using their setters and resultroot parameters.
Inspired by Jason Lengstorf’s recent live stream Turn Any Data Source into GraphQL, which covered wide ground thanks to Jason and Carlos’s steady Postman handling, I resolved to use Postman while designing this StepZen schema–a wise choice, as it began saving the day pretty much instantly.
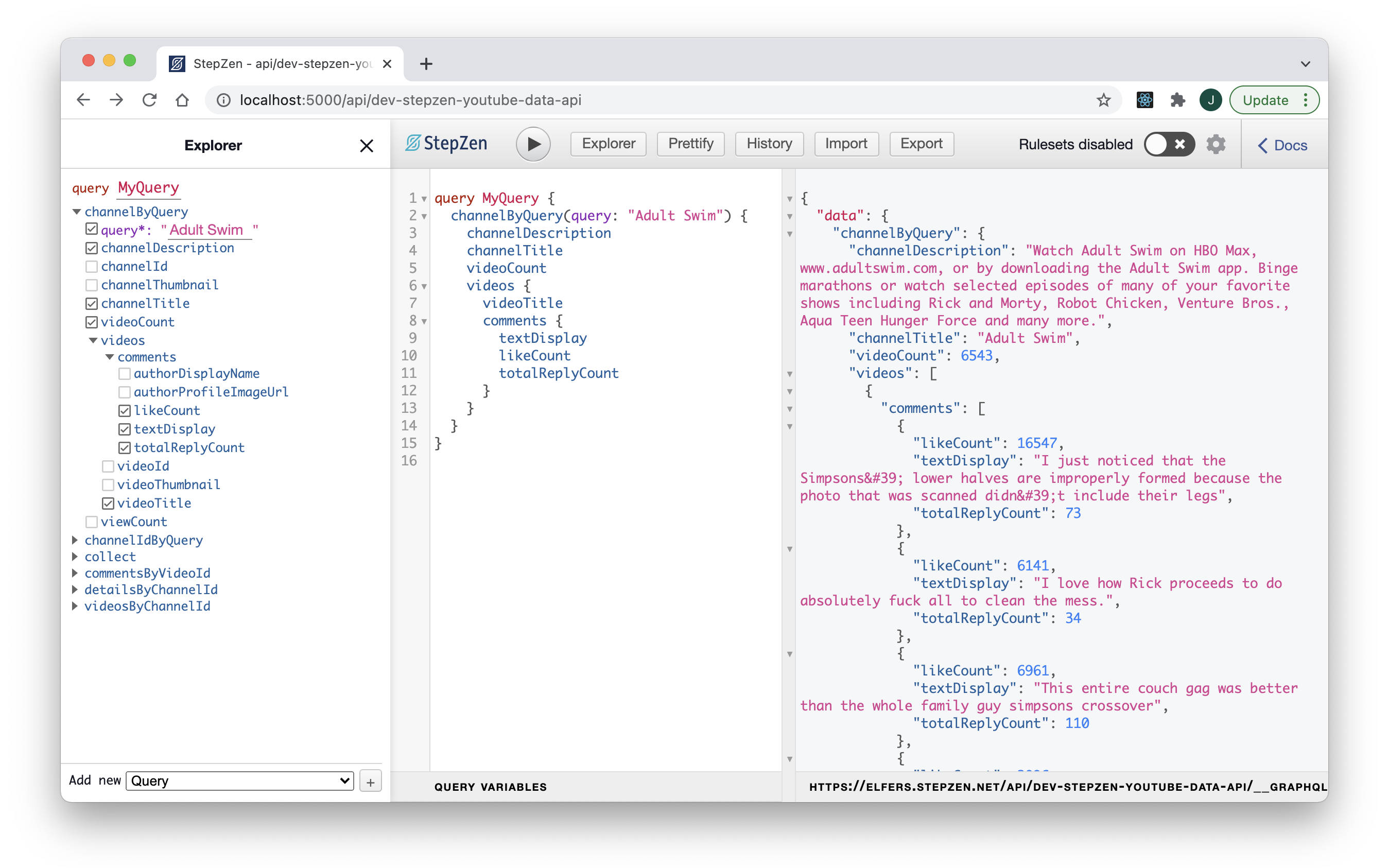
Orchestrating the four GETs this sequence required may not sound impossibly challenging, but composing them using my standard tools–ie. a Next.js dev terminal and a Chrome console–would have been impossible on YouTube’s standard API quota. Writing my schema boiled down to a straightforward accumulation of two basic API elements: endpoints and responses. Without Postman as a scratchpad reference for those query endpoints and JSON responses, keeping track of everything across multiple windows would’ve been worse than inconvenient–I’d have blown through days of quota limits just on incidental reloads.
Custom-aggregated YouTube-Data-as-GraphQL
As it was, with my StepZen GraphiQL and Postman Workspace side-by-side, I was able to achieve something remarkable: a localhost and live endpoint serving custom-aggregated YouTube-Data-as-GraphQL, after barely a day-and-a-half of experimentation. (But literally overnight–I only had a few syntax questions for the StepZen Discord the next morning.)
Which is not to say all my API workflow problems were magically solved. Even with my queries saved on Postman and cached at StepZen, I also ran into quota limits when it came to calling and sorting data on the client side–problems and solutions I’ll examine in closer detail next time.
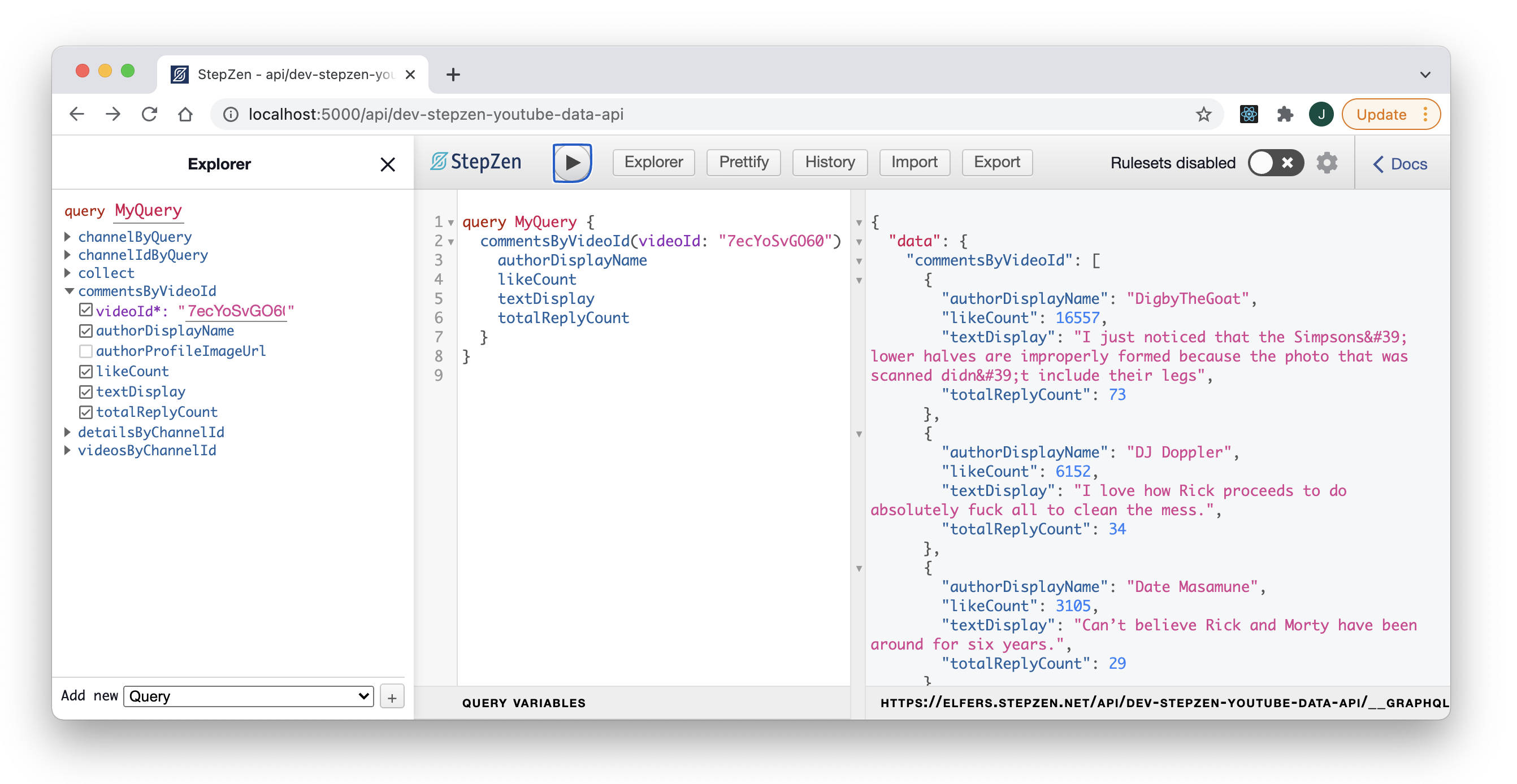
For the moment, though, I’d like to end on the same GraphiQL Explorer view that gave me pause during development, something scarily close to human-readable JSON. When I saw my schema reflected back to me like this–not just sculpted but intelligible, virtually readable–I knew I’d stumbled upon a necessary feedback loop, and an important new workflow for API development.
Helpful resources:
- This project: stepzen-youtube-data-api repo on GitHub
- How to Connect to a REST Service (StepZen Docs)
- How to Create a Sequence of Queries (StepZen Docs)
- StepZen Community Discord.


