The Case for a Federated Data Access Layer with GraphQL

 Anant Jhingran
Anant JhingranThe problem of data being siloed across multiple systems, yet applications wanting one view of the data, has been a universal one for decades.
Traditionally, there are three parts to effectively achieving one view of the data:
- A metadata view of enterprise data sources. Data catalogs or integration hubs typically specialize in these.
- A uniform approach to accessing all the data sources, leveraging the metadata.
- A runtime that supports translations and executions across all the backends.
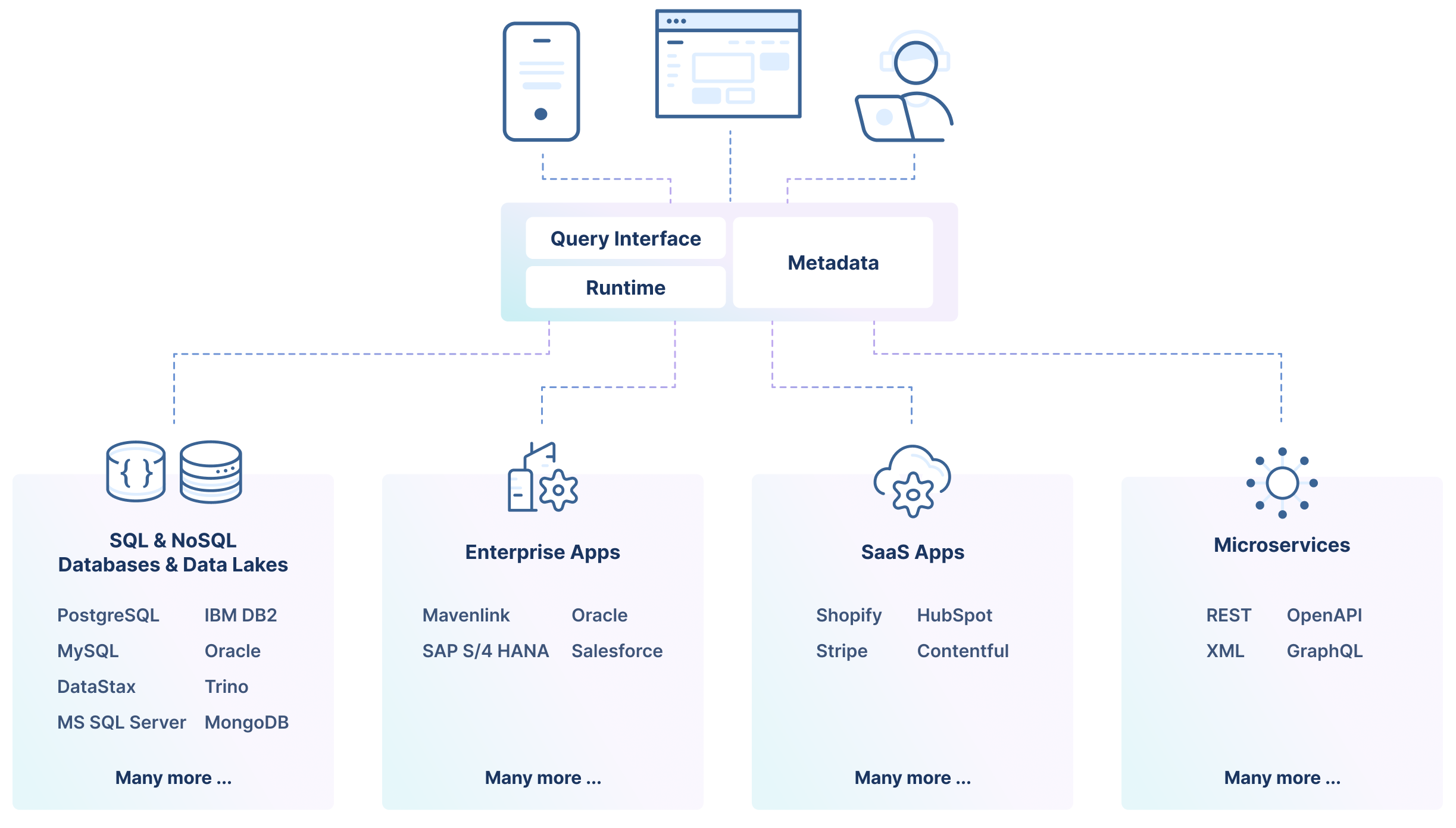
Federated Data Access
Gartner and others are beginning to describe these parts and the best practices surrounding them as data meshes or data fabrics. The exact terminology is not relevant (and no two people will agree on what any one term means), but what is important is that this is viewed as a “federated data access tier.”
There are many technologies that federate over some subset of data sources. For example, Trino is a popular choice for federating over SQL backends. And there are specialized technologies for data catalogs, such as Alation and Informatica’s Integration Hub. In this article, we assert that GraphQL lays claim to an important piece of the puzzle. It’s not that GraphQL has all the capabilities that a Trino has or that its understanding of metadata is as powerful as a data catalog. But there are three very specific reasons why GraphQL is an excellent federated data access tier:
- GraphQL can handle any backend, not just relational databases. It is based on JSON data merging, and JSON is much better than a table representation of databases as a universal representation of a wide variety of data sources.
- GraphQL is designed for ease of consumption. A GraphQL query is easy to write, with no complex outer joins, equality clauses, case statements, etc. Of course, ease of consumption means that it does not have the full flexibility of SQL, but we believe that the tradeoffs it makes are exactly right — they support a better developer experience and democratize access to the data.
- Perhaps, most importantly, good GraphQL servers balance the three parts needed to effectively achieve one view of the data — metadata, query and runtime — in an iterative manner. What that means is that you are not building a data catalog before a use case has emerged. Or designing query specs for some future, ideal space. As you bring in more backends, you expand your metadata, expand your query scope, and always have a running runtime. And the federated data layer can itself be a federation of federated data layer — turtles all the way down, leading to organizational efficiencies. Let’s elaborate on each of these.
Handling Heterogeneous Backends
Let us say that a frontend developer wants a “view” of a logged-in customer and all their orders and each order’s delivery status. Customer data may come from a microservice that returns the data in a JSON format. Order data might come from a database returning flat tabular data. And delivery status might come from a SOAP service that returns XML format. One could denormalize the data from each into its tabular structure and then join across, producing a massive denormalized table that the frontend developer must parse and restructure into a nested format. Alternatively, one could convert all data into a JSON format and stitch things together, leading to efficiencies in data generation and ease for the frontend developer.
When data comes from heterogeneous backends and the frontend applications need JSON, it is better to treat all backends as JSON producers and the middleware as a JSON stitcher. And this is the view of GraphQL and why it is natural for these use cases.
Ease of Consumption
The power of the federated data tier is that it abstracts away the backends. What good is it if those abstractions add cognitive complexity for the frontend developers? Compare this:
select
row_to_json(cod) as customers
from
(
select
c.*,
json_agg(
row_to_json(od.*)
) as orders
from
customer c
left outer join (
select
o.*,
json_agg(
row_to_json(d.*)
) as deliveries
from
orders o
left outer join (
select
*
from
delivery
) d on (d.orderid = o.id)
group by
o.id,
o.customerid,
o.carrier
) od on (c.id = od.customerid)
where c.email = ‘john.doe@example.com’
) cod
With a three-level query in GraphQL:
{
customer (email: “john.doe@example.com”) {
name
orders {
carrier
delivery {
status
}
}
}
}
Clearly, the latter GraphQL query is much easier and more intuitive for frontend developers. (The author has been doing SQL for a very long time but still has to look up complex queries, and the json_agg syntax is so complicated and non-standard.)
GraphQL has been touted as reducing data transfer. It does. But that is only one reason for its popularity. It is very intuitive and enables the frontend developers to ask for, and get, exactly what they want.
Iterative Approach to Federation
With any cross-enterprise initiative, you have be very practical. Building a metadata catalog is well and good, but is it putting the cart before the horse? Good GraphQL implementations (such as StepZen’s) pull in just enough metadata to ensure that queries can be scattered to various backends correctly and gathered (stitched) correctly. As more backends are brought in, the metadata information gets richer, but so do the query possibilities. Because the runtime keeps up with the metadata, the system is always up and running and provides the usefulness of the data and query at all times.
Furthermore, by having stitching naturally built into it, GraphQL enables federation across teams. So an enterprise can have an e-commerce team, a marketing team and a supply chain team each building its own federated data layer, and yet the enterprise can federate over these federated layers. The only difference is that for the enterprisewide federated layer the backends would be GraphQL backends, not database or REST or SOAP backends.
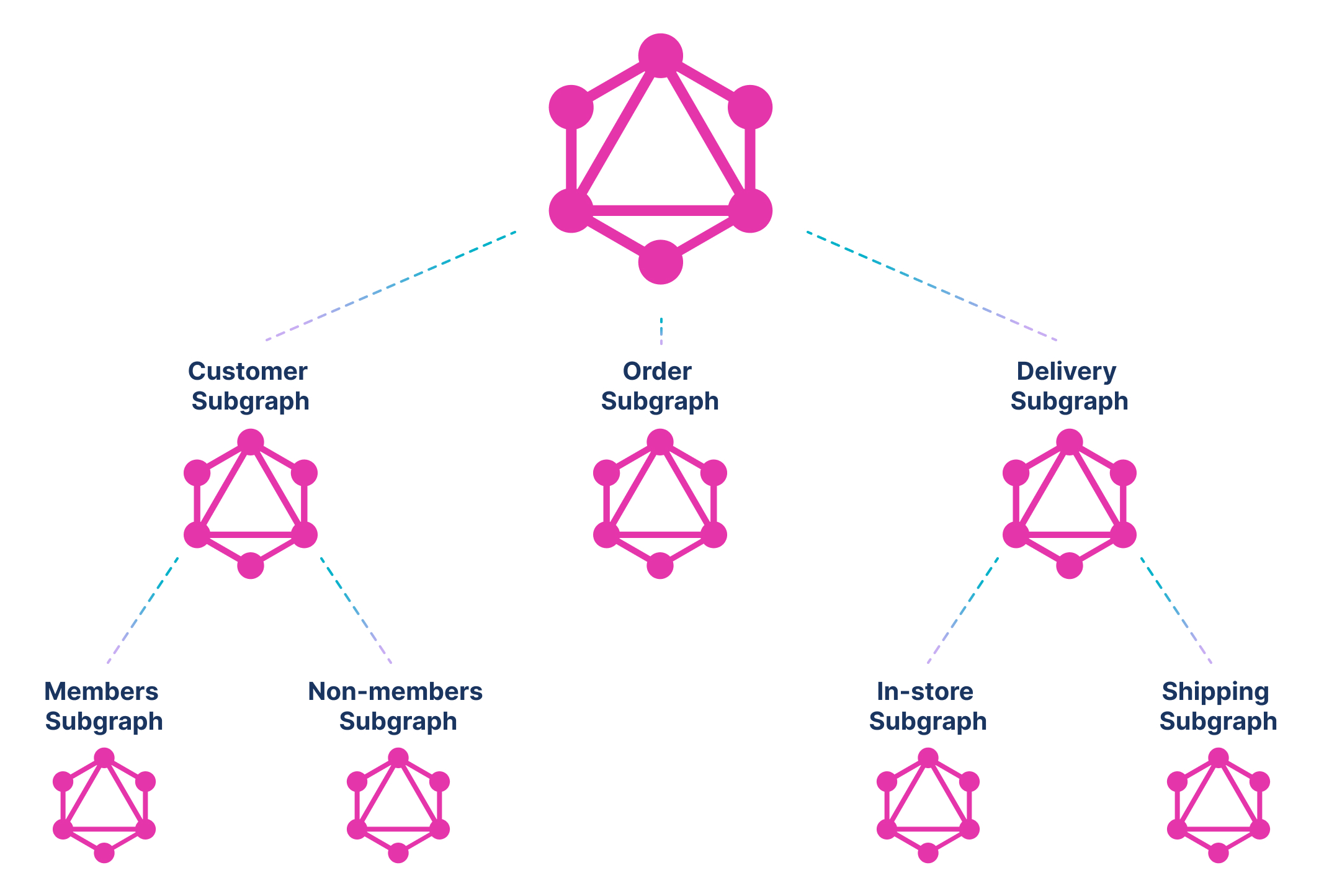
Summary
While we are still in the early innings of truly enterprisewide federation architectures, we are very bullish on GraphQL providing a major underpinning of this advancement. We believe that while individual technologies like data catalog and SQL federation have a role to play, the GraphQL approach leads to faster time to value across a much larger and heterogeneous set of backends.
Of course, not all GraphQL implementations are the same. At StepZen, having learned a lot from databases, we have taken a declarative approach to how this layer is built. This approach enables the team building the federated layer to focus on the needs of the frontend developers and the capabilities of the backend systems and leave the hard job to the middleware.
Visit stepzen.com to read about StepZen's approach to declarative GraphQL Federation. We'd love to share more and learn what you're working on - book a short call.
This article was originally published in The New Stack: 


